Sparkling Vertex AI Pipelines
How to deploy a simple Spark ML pipeline using Vertex AI Pipelines

Updates
- Apr 11, 2022: Vertex AI pipelines supports Dataproc Serverless components for Vertex AI Pipelines now. With those components, you have native KFP operators to easily orchestrate Spark-based ML pipelines with Vertex AI Pipelines and Dataproc Serverless.
All right, you talk, I’ll listen!
Do you have any ideas about Data Science on Google Cloud you would like to see? Please let me know by filling out this form. This would help me on future blog posts =)
Disclaimer
This article assumes that you already have some prior knowledge of MLOps, machine learning pipelines and Vertex AI. In case you don’t, I would recommend watching these videos from Priyanka Vergadia for a quick overview: Introduction to MLOps and Vertex Pipelines and End-to-end MLOps with Vertex AI.
Premises
Vertex AI Pipelines is one of the most powerful services of the Vertex AI MLOps features launched this year on Google Cloud.They make it really easy to orchestrate machine learning workloads using Kubeflow. Indeed, you can do almost anything inside a pipeline component. And you’re not limited to certain Vertex functions.
So what if you have a PySpark ML pipeline?
In this article, we’ll illustrate that generality by using Spark inside some Vertex Pipeline components. In particular, I will show how to use Vertex AI Pipelines in conjunction with Dataproc to train and deploy a ML model for near-real time predictive maintenance application.
Our scenario
Imagine you are a ML engineer, and now that your company is moving to the cloud, you’ve been told to lead a proof of concept and prove how to train a predictive maintenance pipeline. Basically, the goal is to process machine log files loaded from on-prem to cloud continuously for training and deploying a ML pipeline you already built on prem.
Regarding the process, you need to become more independent on running (ML) workloads compared in order to speed up the experimental phases¹. Also we need to adopt MLOps practices to make the process reliable, scalable and reproducible across the team.
At the end, you found that Vertex AI Pipelines accomplishes all of this.
Indeed, you will be able to submit ML jobs with Kubeflow based technology, which we assume you are already familiar with compared to other cluster orchestration tools like Workflow. Also, they enable you to track artifacts and lineage of data, feature, model and experiment metrics across your ML workflow with the associated metadata store and the other Vertex AI services such as Datasets, Feature Store and Experiments.
The Dataset
In order to implement this scenario, we use the UCI Machine Learning — AI4I 2020 Predictive Maintenance dataset, which is a synthetic dataset that reflects real predictive maintenance data encountered in industry. It consists of 14 features associated with the machine process such as process temperature, rotational speed and torque. And the target machine failure label indicates whether the machine has failed for at least one of the defined failure modes.
The Anatomy of our Pipeline: Architecture, Components and Representation
About Vertex AI Pipeline, we assumed that
each component of the pipeline has to create a Dataproc cluster, process a PySpark job and destroy the cluster.
Someone could argue that this pattern adds extra running time. That’s true, but each step of the pipeline may need different amounts of resources and then it would need a different cluster configuration. One example could be the hyperparameter tuning step which generally needs more processing power. Also, one of the advantages of using Dataproc is related to the idea of ephemeral clusters which gives more control and more flexibility at the same time.
With that said, below you can find the Pipeline Architecture
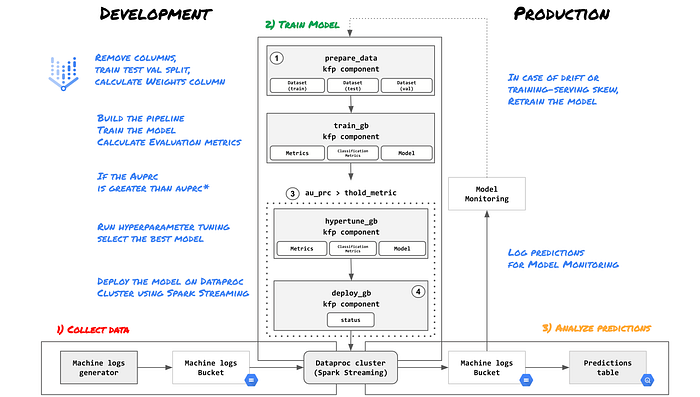
Looking at its components, you have:
- prepare_data component to ingest data, do some simple data preparation and creates Vertex Datasets to train model and evaluate the model
- train_model component to train a one simple GBTClassifier using PySpark MLlib library, calculate several classification metrics such as areaUnderPRC, confusion matrix, accuracy and log them using Vertex Metadata²
Then if the area under the precision-recall curve³ is greater than a predefined metric threshold:
- hypertune_gb component finds the best model and parameters using ParamGridBuilder and CrossValidator methods. All metrics and hypertuning metadata are stored in the pipeline lineage again using metadata service.
- deploy_gb component deploys the final model on Google Cloud Dataproc cluster using Spark Streaming
Once you figure out each component, you can implement them using Kubeflow Pipelines SDK.
Indeed, at the time I’m writing, there is no pre-build component to interact with Dataproc in the Google Cloud Pipeline Components SDK. But you can always build custom ones!
In our case, because the assumption we made, the component needs to use Dataproc SDK to:
- Create the Dataproc cluster
- Check the Cluster state
- Submit the Pyspark Job
- Check the Job state
- Delete the cluster
To start, one way to build a pipeline component is via decorator. For example, for the train_model component we have
@component(base_image="gcr.io/google.com/cloudsdktool/cloud-sdk:latest", packages_to_install=["google-cloud-dataproc==2.5.0", "google-cloud-storage==1.41.1", "scikit-learn==0.24.2"], output_component_file="2_sparkling_vertex_train_gb.yaml")def train_gb(project_id:str, region:str, bucket_name:str,
cluster_spec:str,
train_dataset:Input[Dataset],
test_dataset:Input[Dataset],
val_dataset:Input[Dataset],
metrics: Output[Metrics],
graph_metrics: Output[ClassificationMetrics],
model: Output[Model])-> NamedTuple("Outputs",
[("metrics_dict", str),
("thold_metric", float),
("model_uri", str),
("train_dataset_uri", str),
("val_dataset_uri", str),],):
Once you import libraries and define variables, you create the PySpark job configuration required to the Dataproc API.
train_gb_pyspark_job_spec = {
'reference': {
'project_id': project_id,
'job_id': train_gb_job_id
},
'placement': {
'cluster_name': cluster_name
},
'pyspark_job': {
'main_python_file_uri': f'gs://{bucket_name}/train_gb.py',
'args': ['--project-id', project_id,
'--bucket', f'gs://{bucket_name}',
'--train-uri', train_dataset.uri,
'--test-uri', test_dataset.uri,
'--metrics-file', metrics_file_name,
'--model', model_name]
}
}Then you can wrap one method for each task we mention in the component⁴. Below you can find an example of a method to submit a Pyspark job using Python Client for Google Cloud Dataproc API.
def _submit_pyspark_job(project_id, region, job_spec): # create the job client.
job_client = dataproc.JobControllerClient(
client_options={
'api_endpoint':
f'{region}-dataproc.googleapis.com:443'
})
# create the job operation.
job_op = job_client.submit_job_as_operation(
request={"project_id": project_id,
"region": region,
"job": job_spec}
) result = job_op.result()
return result
Finally, you submit the job and you can use built-in Kubeflow SDK functionalities to leverage Vertex Pipelines capabilities like Metrics and Metadata. For example, if you want to log training metrics we would have
# submit the job
print(f"Submitting job {train_gb_job_id}.")
job_result = _submit_pyspark_job(project_id, region,
train_gb_pyspark_job_spec) if _check_job_state(project_id, region,
train_gb_job_id) == 'state.done':
print(f"Job {train_gb_job_id} successfully completed.") else:
raise RuntimeError(f'Job {train_gb_job_id} failed.'
f'Please check logs.') # -------------------------------------------- # log metrics
metrics.log_metric("areaUnderROC", area_roc)
metrics.log_metric("areaUnderPRC", area_prc)
metrics.log_metric("Accuracy", acc)
metrics.log_metric("f1-score", f1)
metrics.log_metric("Precision", w_prec)
metrics.log_metric("Recall", w_rec)
with with _check_job_state as a helper method to get the job status and all metrics are pre-calculated.
Of course, the intent here is to provide a possible approach. There are other possibilities you would like to explore. By the the end, if you use the same design for each step, we will have all four components and will get the following pipeline representation
@kfp.dsl.pipeline(name=f"pyspark-anomaly-detection-pipeline-{ID}", pipeline_root=PIPELINE_ROOT)
def pipeline(project_id:str = PROJECT_ID,
region:str = REGION,
bucket_name:str = BUCKET,
cluster_spec: BASE_CLUSTER_SPEC,
raw_data: str = RAW_DATA_PATH,
thold: float = AUPR_THRESHOLD,
stream_folder: str = STREAM_FOLDER
):
"""
Combine prepare_data, train_model, hypertune_gb and deploy_gb components in order to train and serve the predictive maintenance model.
Args:
project_id: The name of pipeline GPC project
region: The region where the pipeline will run
bucket_name: The bucket name where training data are stored
cluster_spec: The basic cluster spec to run pyspark jobs
raw_data: The name of training data source
thold: The minimum performance threshold to deploy the model
stream_folder: The name of folder to store the predictions
"""
# Create the prepare_data operation to get training data
prepare_data_op = prepare_data(
project_id=project_id,
region=region,
bucket_name=bucket_name,
cluster_spec=cluster_spec,
raw_file=raw_data)
# Create the train_gb operation to train and evaluate model
train_gb_op = (train_gb(
project_id=project_id,
region=region,
bucket_name=bucket_name,
cluster_spec=cluster_spec,
train_dataset=prepare_data_op.outputs['train_dataset'],
test_dataset=prepare_data_op.outputs['test_dataset'],
val_dataset=prepare_data_op.outputs['val_dataset'])
.after(prepare_data_op))
# Set Condition to validate the model compared au_prc threshold
with Condition(train_gb_op.outputs['thold_metric'] > thold,
name=AUPR_HYPERTUNE_CONDITION):# Create the hypertune_gb operation to hypertune and evaluate model
hypertune_gb_op = (hypertune_gb(
project_id=project_id,
region=region,
bucket_name=bucket_name,
cluster_spec=cluster_spec,
train_dataset_uri=train_gb_op.outputs['train_dataset_uri'],
val_dataset_uri=train_gb_op.outputs['val_dataset_uri'])
.after(train_gb_op))
# Create the deploy_op to deploy the model on Dataproc cluster
deploy_gb_op = deploy_gb(
project_id=project_id,
region=region,
bucket_name=bucket_name,
cluster_spec=cluster_spec,
stream_folder=stream_folder,
model=hypertune_gb_op.outputs['tune_model'])
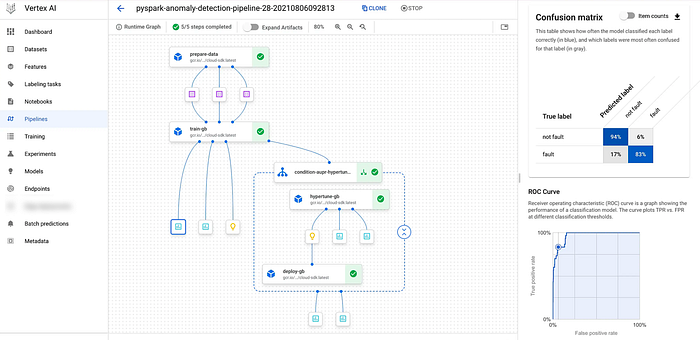
Below you can see how the execution graph looks like once you submit the pipeline to Vertex AI
Bonus: Simulate near real-time predictions
For demo purposes, you can also simulate near real-time predictions where data is loaded to the staging bucket and the model generates predictions deployed on Google Cloud Dataproc cluster using Spark Streaming. Below the run_get_prediction_transform function you could use to generate predictions.
def run_get_prediction_transform(args):
bucket = args.bucket
stream_uri = f'{args.bucket}/{args.stream_folder}'
tune_model_uri = args.tune_model_uri
# create a spark session
logging.info(f"Instantiating the {APP_NAME} Spark session.")
spark = (SparkSession.builder \
.master("local") \
.appName(APP_NAME) \
.getOrCreate())
try:
# start prediction process
logging.info(f"Ingest streaming data under {stream_uri}.")
stream_raw_df = (spark.readStream \
.option("header", True) \
.option("delimiter", ',') \
.option("maxFilesPerTrigger", 1) \
.option("rowsPerSecond", 10) \
.schema(DATA_SCHEMA) \
.csv(stream_uri)) logging.info(f"Load model into memory.")
tune_model = CrossValidatorModel.load(tune_model_uri) logging.info(f" Start streaming prediction process.")
gb_prediction_transform = get_prediction_transform(
stream_raw_df,
tune_model) logging.info(f" Run prediction query.")
predictions_query = (gb_prediction_transform \
.writeStream \
.format("console") \
.outputMode("append") \
.queryName("predictions") \
.start())
predictions_query.awaitTermination() except RuntimeError as error:
logging.info(error)
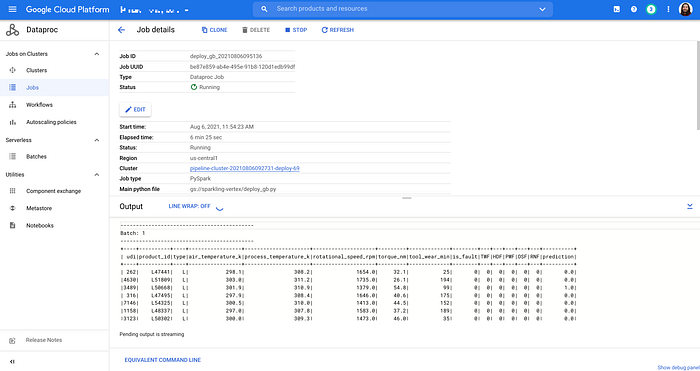
At the end, you review predictions by looking at the log of deploy_gb_2021xxxx job in the Dataproc Jobs UI.
What’s Next
In this article, we explored how to use Vertex AI Pipelines in conjunction with Cloud Dataproc to train and deploy a ML pipeline using Spark MLlib. We made some assumptions about the scenario and we imagined one possible pipeline architecture that would do it. Finally we showed how to implement the pipeline using Kubeflow Pipelines SDK and how it is possible to simulate near real-time predictions using Spark streaming.
We could do so much more. For example, we didn’t cover model monitoring here. Realistically, we could build a custom serving container to deploy SparkML models and then monitor them leveraging Vertex Monitoring and its integration with Vertex Prediction. Also, Google Cloud recently announced a new partnership with Databricks and we could also explore several integration use cases along MLFlow and Vertex AI platform.
For now, I hope you enjoyed the article. If so, clap it or leave comments. Also if you’d like to know more about this scenario or you have ideas about ML content you would like to see, feel free to reach me on LinkedIn or Twitter and let’s talk about it.
Till the next post…
Thank you to Marc Cohen and Brad Miro for their feedback. Thanks to Gianluca Ruffa who teaches me the art of “Build, Document, Package and Publish”.
References
- https://cloud.google.com/vertex-ai
- https://cloud.google.com/architecture/using-apache-spark-dstreams-with-dataproc-and-pubsub#creating-a-service-account-for-dataproc
- https://github.com/GoogleCloudPlatform/vertex-ai-samples
- https://googleapis.dev/python/aiplatform/latest/index.html
- https://google-cloud-pipeline-components.readthedocs.io/en/google-cloud-pipeline-components-0.1.5/index.html
- https://spark.apache.org/docs/latest/index.html
- https://spark.apache.org/docs/latest/ml-guide.html
¹ The scenario is strictly related to the experience that I have. Indeed, I see that it takes a long time for ML engineers before they can submit model training when orchestration is up to who manages the cluster’s environment and its tools.
² For the sake of simplicity, I train just one model. But you can replicate the same component as many times you want.
³ I choose that metric because of the unbalanced use. Of course, you can choose the one that fits with your problem.
⁴ Wrapping methods in the component is suggested. Another way would be to include it as a package to install.

